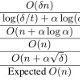Abstract:Recent technological advances have greatly increased the ability to acquire, store, and analyze data. These developments have significantly improved the potential of many commercial and scientific applications, and lead to many new scientific discoveries. We are growing accustomed to accessing massive amounts of information from almost anywhere using devices ranging from cell phones and tiny GPS navigation systems, to ordinary computers and beyond. The large amount of information available presents a number of problems and opportunities. One of the main obstacles is most software is not designed to handle large amounts of data, resulting in crashes or running for a very long time on even moderately-sized data sets. Another problem is contemporary memory devices can be unreliable due to a number of factors, such as power failures, radiation, and cosmic rays. The content of a cell in unreliable memory can be silently altered and this can adversely affect most traditional algorithms. The focus of this dissertation is on the algorithms and data structures specifically designed for solving a number of the problems involving large data sets and unreliable memory devices. The dissertation is divided into two parts. In Part I, we use the classical external memory model by Aggarwal and Vitter, and the cache-oblivious model recently proposed by Frigo et al., to design cache-efficient algorithms. We focus on problems involving terrain models which, due to modern terrestrial scanning techniques, can be very large. We present the TerraSTREAM software package, which solves many common computational problems on big terrains. We also present an I/O-efficient algorithm for computing contour maps of a terrain and a cache-oblivious algorithm for finding intersections between two sets of internally non-intersecting line segments. In Part II we use the faulty memory RAM, proposed by Finocchi and Italiano, to model unreliable memory circuits and design algorithms that are resilient to memory faults. We present a resilient priority as well as an optimal comparison-based resilient algorithm for searching in a sorted array. We also show how to use this algorithm to get a dynamic resilient dictionary. Finally, we present a model that combines the standard external memory model with the faulty memory RAM and present lower and upper bounds for I/O-efficient resilient dictionaries, an I/O-efficient resilient sorting algorithm and an I/O-efficient resilient priority queue.

")
 @thomasmoelhave
@thomasmoelhave